前言
OpenNMT 是一个开源神经网络机器翻译项目, 许多出名的工作都是在这个项目之上进行的. 目前它主要有3个实现:
- OpenNMT-lua, 是该项目最初的实现, 采用了 LuaTorch. 里面包含了所有的 feature.
- OpenNMT-py, OpenMNT-lua 的一个 clone, 采用 pytorch, 比较适合 research.
- OpenNMT-tf, 使用 tensorflow 的一个实现版本, 主要侧重于大规模训练.
最近一段时间在学习 OpenNMT-py 的源码, 因此把一些总结和心得记录在此.
源码阅读
Data Loader
OpenNMT-py 的 data loader 部分代码结构比较复杂, 这也是为了让代码有比价好的泛化性能,并支持多类型数据(如audio, image等). 本次先以 text 数据为例. OpenNMT-py 的 Dataset 模块是在 torchtext 库的基础上建立的. torchtext 中有以下主要概念:
- example, 定义了一个单独的训练或者测试数据
- field, 负责数据处理. 处理步骤包括 preprocess, process, postprocess. 具体分工之后细说
- batch, 将 example list 通过 field 处理为 batch tensor
- dataset, 负责存储 examples 和 field
- iterator, 定义 dataset 里 examples 的迭代方式
它们在 OpenNMT 中都被包上了一层, 具体实现是这样的:
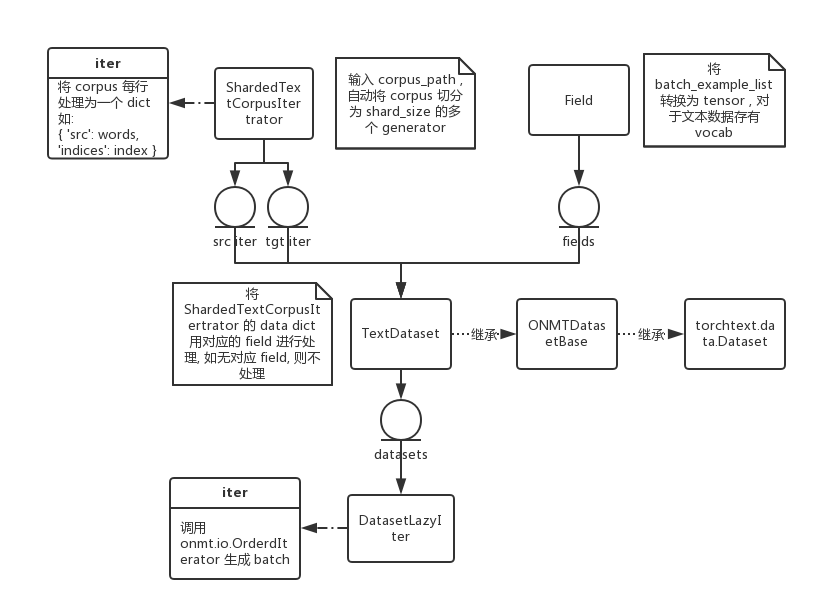
首先是 ShardedTextCorpusIterator 负责读取原始文本, 并将每行处理为一个 data dict. 在机器翻译中, src_iter 和 tgt_iter 连同它们的 Field 一起用来构建 TextDataset. 在 TextDataset 的构造函数中,调用了 \_construct\_example\_fromlist 来进行数据的 preprocess:
def _construct_example_fromlist(self, data, fields):
"""
Args:
data: the data to be set as the value of the attributes of
the to-be-created `Example`, associating with respective
`Field` objects with same key.
fields: a dict of `torchtext.data.Field` objects. The keys
are attributes of the to-be-created `Example`.
Returns:
the created `Example` object.
"""
ex = torchtext.data.Example()
for (name, field), val in zip(fields, data):
if field is not None:
setattr(ex, name, field.preprocess(val)) # preprocess 主要是数据的 tokenize 等工作.
else:
setattr(ex, name, val) # 如无对应 filed ,则不处理
return ex
构建好 datasets 之后便交由 DatasetLazyIter. 其 __iter__ 函数实际上调用的是 omnt.io.OrderedIterator (继承自 torchtext.data.Iterator) 来生成最终的 batch.
class Batch(object):
"""Defines a batch of examples along with its Fields.
Attributes:
batch_size: Number of examples in the batch.
dataset: A reference to the dataset object the examples come from
(which itself contains the dataset's Field objects).
train: Whether the batch is from a training set.
Also stores the Variable for each column in the batch as an attribute.
"""
def __init__(self, data=None, dataset=None, device=None, train=True):
"""Create a Batch from a list of examples."""
if data is not None:
self.batch_size = len(data)
self.dataset = dataset
self.train = train
for (name, field) in dataset.fields.items():
if field is not None:
batch = [x.__dict__[name] for x in data]
setattr(self, name, field.process(batch, device=device, train=train))
可以看出这里的调用了 field 的 process 函数, 主要负责 pad 和 numericalize.
Model
待续…